2026-06-02T12:59:32+00:00https://lil.law.harvard.edu/The Library Innovation Lab at Harvard UniversityThe Library Innovation Lab is growing knowledge and community by bringing library principles to technological frontiers.An Automated Data Monitoring Toolkit and the AI Benchmarking Exercise at the Public Data Project2026-06-02T13:00:00+00:002026-06-02T13:00:00+00:00https://lil.law.harvard.edu/blog/2026/06/02/an-automated-data-monitoring-toolkit-and-the-ai-benchmarking-exercise-at-the-public-data-project/This post is being shared on both the dataindex.us newsletter and the Library Innovation Lab Blog.
“Is data changing? Is it being disappeared? How do we know? How can we know?” This interrogative refrain rang through just about every conversation I had when, almost a year ago, I came to Harvard Law School Library to lead the Public Data Project. Thanks to the dataindex.us Data Checkup, a plan is in place to do this complicated but essential work. Through the careful scaffolding dataindex.us has constructed and the assiduous research of its staff, more than a dozen federal datasets have “health assessments” and the team continues to add to this list.
In October 2025, the Public Data Project partnered with dataindex.us to develop a data monitoring toolkit that could both work at scale and be user driven. In addition to creating an automated tool that can process large numbers of datasets, we also want the user to determine which datasets they want to monitor. Let’s face it, when it comes to federal data, one person’s byzantine, inscrutable dataset is another person’s trove of invaluable ground truth. The anecdotes of data use collected by essentialdata.us offer varied examples of the ways people benefit from federal datasets. The range of uses are a clear indication that people need to be able to monitor the data that matters to them.
At the Public Data Project, we are creating a toolkit that will enable users to detect and monitor changes to federal datasets over time. It will enable users to select a dataset and track changes within the data itself, as well as to automate the monitoring of external sources that indicate whether the data might be changing. Indicators of change to a given dataset range from somewhat obvious sources, like major news sites, to more obscure sources, like the U.S. Code. At present, our tool development has produced two components.
First, Binoc is a command line tool and library to generate changelogs for datasets that don’t have them.
Unlike generic diffing utilities intended to describe line-level differences in plain-text content such as source code or Markdown, Binoc aims to efficiently summarize changes in real-world datasets, including file additions and deletions, row-level updates, and schema alterations. Given a series of dataset snapshots captured at different points in time, Binoc detects what changed, expresses any changes as a minimal structured diff, and produces a human-readable summary. Binoc is currently in a collaborative design phase of development, with new features being added regularly. We welcome feedback from early adopters.
We have also begun the research for a second component of the data monitoring toolkit development.
We have created an AI benchmarking exercise to compare and to evaluate how well AI can monitor data and assess its risk when considered next to the processes and conclusions of a careful researcher. The goals of the exercise are to:
Test how well AI can assess various types of risk to federal datasets;
Evaluate what baseline a popular search model would use to answer those without a custom search harness;
Surface and reflect on the tacit knowledge necessary to perform risk assessment, including the sources needed, the steps involved, and the difficulty of defining criteria;
Create awareness and community through an intellectually engaging activity that includes both individual research and group reflection.
We have conducted an initial test run of this exercise with a group of 10 information professionals. After introducing the participants to the dataindex.us rubric to assess the risk level of a given dataset, each participant was assigned a dataset and asked to evaluate it across three of the six risk dimensions outlined in the rubric. Each participant was either assigned the first three dimensions — Historical Data Availability, Future Data Availability, and Data Quality — or the latter three — Statutory Context, Staffing and Funding, and Policy. For the first hour, participants more or less worked alone, diligently researching a subject that they lacked expertise in, but which they had clear guidelines for the kind of information they sought. Participants then opened ChatGPT, and fed it prompts that we had scripted and tailored for each dataset. First in a form that asked them specific questions and then as a group compared their results with ChatGPT’s, participants reflected on their findings. Going through their three assessment dimensions, participants compared their conclusions to that of AI’s, reflecting on what AI missed, what they missed, and on what parts of the rubric may have led to confusion.
This exercise gave us an early insight into the potentials and pitfalls of AI’s ability to assess data risk, as well as ways in which we might tweak both the exercise and the assessment rubric. This group of participants were information professionals, not policy wonks, and we are eager to see how area specialists’ experience might lead to different outcomes in this exercise. In addition, we want to experiment with prompt engineering and give participants more leeway in their interaction with AI. In the next iteration of the exercise, we will rely on the transcription of each participant’s interactions with AI for analysis, rather than asking individuals to respond in a form.
What we liked most about this exercise, however, was the collective reflections not just on AI, but on public data more generally. One participant described it as an “excellent empathy-building exercise” because, through the work, both alone and as a group, participants become aware of the importance of and perils to public data. They reflected on if and how to translate their own empathetic experience to AI.
]]>
Molly HardyThis post is being shared on both the dataindex.us newsletter and the Library Innovation Lab Blog.]]>
Introducing the Law Skills Hub2026-05-26T00:00:00+00:002026-05-26T00:00:00+00:00https://lil.law.harvard.edu/blog/2026/05/26/introducing-the-law-skills-hub/
A trusted advisor, someone with decades of experience, can help with both small things and big things. Often, the small things come first. Getting the structure of a document right, or unsticking an awkward passage, can clear space for the deeper thinking that follows.
The procedural knowledge of an experienced advisor lives in the space between what they say and what they ask, what they cross out and what they leave, what they teach explicitly and what they only ever model.
A great deal of writing, reformatting, and thinking-through is now happening inside AI agents. The agents are general by design. They start from an average of the public web, which means a student asking one to “fix my résumé” gets an average resume. An advisor’s twenty years of experience is nowhere in that exchange.
We built the Law Skills Hub to see if it was possible to capture, preserve, and share relevant procedural expertise with others and with agents, to empower more meaningful work.
What it is
The Law Skills Hub is a curated, openly licensed collection of agentic skills. Skills are small, structured documents that a user can install in an AI agent, so that the agent has a procedure to follow, not just a prompt to react to. Each skill in the hub has been written or vetted by LIL, published in plain Markdown, and kept under public version control. You can find the hub at lil.law.harvard.edu/lawskills-hub and the underlying repository at github.com/harvard-lil/lawskills-hub. A human can read a skill like a recipe. An AI tool can read it too.
A skill is the codification of a process, a checklist of sorts for how to coach a student writing a public-interest resume, how to scaffold a syllabus around evidence-based learning, how to reformat instructor feedback so it tracks the rubric. The skill carries the steps, the values to check against, the templates the expert would reach for, and the things they would not do. A skill does not replace expertise. It tries to preserve and apply process.
We are launching with a small set of skills already in production, several more in progress, and a contributor guide for anyone who wants to add to the collection.
Why now
Three things became clear over the last several months, working with faculty, with Career Services, and inside the lab.
The first is that AI companies are starting to converge on a standard for agent skill. Anthropic and OpenAI have agreed on a common format and capabilities which you can learn about at agentskills.io.
The second is that, like most things, it is best to meet users where they are. Many people are working in agent software to create and improve knowledge work. People are not, as a rule, going to abandon the agent and come to a library website or use a bespoke tool. If our procedural knowledge is going to be useful, it must travel into the agent the user is already in and ideally into more than one of them, because the agents are interchangeable and people switch between them.
The third is that there is a growing informal economy of skills shared in zip files, gists, and Discord threads. A non-technical user downloading one of these has no easy way to know what is inside, what values it encodes, or whether the code it runs has been read by anyone they trust. Some of those skills are excellent. Some of them quietly do things their users would not endorse.
We think there was room for a different kind of hub. A hub grounded in stewardship and reliability.
A Harvard Law–branded hub on the harvard.edu domain, with skills published as readable Markdown rather than zipped bundles, is our attempt to address both problems at once. The address tells you where the software comes from. The format lets you read it before you run it. We’ve also created “meta skills” which allow people to install one skill that will help them discover and install other skills for them based on their interests.
What we won’t do
Replace human cognition.
The hub has a clear scope, and the contributor guide names it. We are not building skills that produce essays, exam answers, or thought labor on the user’s behalf. The skills we publish coach, reformat, and scaffold—they presume the user has the source material, the question, the work, and that what they want help with is the procedural part. The mechanical, the administrative, the templated.
This is a values boundary, not a technical one. We are a library, and our work has always been about making people more capable of their own thinking, not less.
A librarian’s framing
There is an older form on campus this hub is descended from, even if it isn’t always recognized. The library guide, or LibGuide, is the genre librarians have used for a long time to compact the things people keep asking about, the workflows experts reach for, the curated path through a subject. A skill, in our reading, is a LibGuide an agent can execute.
This frames the work for us in a way we have found useful. We are not, primarily, building software. We are doing something closer to journalism, or to archival fieldwork—sitting with experienced practitioners, recording what they do and how they do it, and turning that record into a document a future user (human or otherwise) can consult. The output happens to be machine-readable.
Not every workflow wants to be a skill. Some procedural knowledge is inseparable from the relationship in which it is taught, and writing it down would flatten it. Part of the work is knowing the difference.
What remains uncertain
We do not yet know how far this approach scales, and we want to say so plainly.
We do not know how large a skill can be before its consistency degrades. Résumé coaching is a useful test case: the work for a private-sector clerkship and the work for a public-interest fellowship genuinely diverge. We are running both as a single skill with branching, and as two specialized skills, and we do not yet know which will produce better outcomes at scale.
We do not know how portable skills are across disciplines. A faculty-feedback skill that works for a 1L torts course may or may not work in a humanities seminar or a wet-lab science. We suspect some skills are portable and some are deeply local; we cannot yet tell you which are which.
These are open questions, not rhetorical ones. The hub is a hypothesis, and the next year of work is testing it.
An invitation
For now, we have a basic site, a public repository, and a small but growing set of example skills. We are continuing to refine what is already there, add new skills, and learn where the approach holds and where it begins to fray.
We are hoping to talk with more people who are willing to share procedural knowledge with us. Sometimes that means a formal contribution. Sometimes it means an issue or a pull request. Sometimes it just means a conversation where we record how someone thinks through a recurring task, what they notice, what they warn against, and what they have learned.
If you are an institution thinking about something like this on your own campus, we would rather collaborate than duplicate. The hub’s value grows if other libraries are stewarding their own skills.
We’d love for you to take part.
]]>
Jenevieve Haggard
A trusted advisor, someone with decades of experience, can help with both small things and big things. Often, the small things come first. Getting the structure of a document right, or unsticking an awkward passage, can clear space for the deeper thinking that follows.]]>
Libraries and Public Access to Federal Data: Chris Marcum Talks to the Public Data Project2026-05-14T16:00:00+00:002026-05-14T16:00:00+00:00https://lil.law.harvard.edu/blog/2026/05/14/libraries-and-public-access-to-federal-data/
On May 7, 2026, Molly Hardy, Project Lead for the Public Data Project, sat down for an interview with Chris Marcum, Senior Fellow for Data Policy at the Data Foundation and former Senior Statistician at the White House Office of Management and Budget. Please click the video above to listen and watch; the interview transcript below has been lightly edited for clarity.
And through his explanation of the flaws in the evidence cited to assess government data loss since 2025, Chris explains the complexities and intricacies of government data collection and distribution, offering those of us in the library community real insights into how we might move forward in our work to preserve and make accessible government data. Government documents and data librarians have been thinking about the preservation and access to government publications for decades. See, for example, James A. Jacobs and James R. Jacobs’s Preserving Government Information: Past, Present, and Future.
And as the Internet Archive’s recent Information Stewardship Forum 2026 on building shared practices for the preservation and access of government information highlighted, librarians, technologists, policymakers, and community advocates need to work together to address the fragmentation and challenges in preserving and accessing government information. And I want to add a quick plug here for the Preservation of Government Information call to action that folks may want to check out and sign that came out of that meeting in San Francisco.
So in February 2025, the Library Innovation Lab announced its archive of the federal data clearinghouse, Data.gov, and our Public Data Project emerged from this effort. In October of last year, we shared Data.gov Archive Search, an interface for exploring this important collection of government datasets. This work builds on recent advancements in lightweight, browser-based querying to enable discovery of more than 311,000 datasets comprising almost 18 terabytes of data on topics ranging from automobile recalls to chronic disease indicators.
So, given his illustrious career in advocating for the preservation and access to government data, the Public Data Project has learned a lot from Chris. And we greatly value this recent report that he’s issued, again, called The Integrity of Public Access to Federal Data. And I’m so pleased today to have a chance to sit down with Chris and ask him to expand on areas of the report that might be of particular interest to the library community. So, welcome, Chris.
Chris Marcum:
Thanks so much, Molly. I’m super excited to be here. I’m just tickled that you all at the Public Data Project have asked me to come and speak with you today about the report. And I’m just really, really honored. Thank you.
Public Data Project:
Absolutely. Could you just tell our audience a little bit about your background? I think it’s really fascinating, and it would be helpful for folks to understand where you’re coming from.
Chris Marcum:
Yeah, sure. So first and foremost, I’m an open science advocate, and have been steeped in information policy in the U.S. federal government for over the last five or six years.
But that’s not what I was trained in: I have a PhD in sociology, and I did a postdoc in economics and statistics at Rand Corporation, where I was looking at vaccination uptake behavior during the H1N1 potential pandemic that didn’t turn out to be a pandemic thanks to high-quality data shared by the CDC. And the late Dr. Nancy Cox was able to share that data.
So eventually I ended up at the NIH. I was doing basic research as a methodologist on biobehavioral health and social networks in the context of heritable health disease. And I started getting this policy itch. I was like, we write really, really great research papers. We produce a lot of amazing data. But ultimately, the impact of that is pretty limited. We’re talking to a very narrow audience of other researchers. And I really wanted to have a broader impact.
And so I started looking for opportunities to do more policy-related work. And NIH is not a policy-setting agency outside of the NIH itself. And so I wanted to really think about how to cut my teeth in policy.
So I joined some committees in the intramural research program. We have a scientific review committee that’s like the Center for Scientific Review for extramural [research], where we were reviewing other intramural scientists’ research. And then I got involved in the data access committees. And that really accelerated my interest in information policy. I was able to go over to help set up a new program in the Office of the Director at NIAID — National Institute of Allergy and Infectious Diseases — called the Office of Data Science and Emerging Technologies. And that was done right at the start of the pandemic. So work there was done really in data sharing and training, and training people how to share effective data, standing up a new data access committee.
And that launched me into the national stage, where I ended up being invited to President Biden’s Fast Track Action Committee on Scientific Integrity. And that led Alondra Nelson at the White House Office of Science and Technology Policy to invite me to lead open science for the Biden-Harris administration, all the way before I got to OMB later on. So it’s been a long, winding career road.
Public Data Project:
That’s fascinating. It’s such an intersection of direct policy work, as you say, as well as the work that we in libraries are concerned with around preservation and access. It’s really great to have your perspective here.
And so if you don’t mind, we’ll just go ahead and jump into the report. And we librarians, we love lists. We love indexes. We love bibliographies. We love catalogs, right? And so a point that you repeatedly returned to in the report, one that I really took to heart, is that the Federal Data Catalog, often referred to as the FDC, is neither a repository nor is it a stable indicator of data accumulation or loss.
So I’m wondering: can you tell us what it is then? That is to say, how is it best understood? And if you could explain the relationship between the Federal Data Catalog and Data.gov, that would be really helpful.
Chris Marcum:
Yeah, this is a nuance in federal information policy that is not well understood or appreciated, even by the members of Congress who, ostensibly anyway, should have an interest or a stake here. So the Federal Data Catalog is a statutory requirement in the Foundations for Evidence-Based Policymaking Act. It’s in Title II, which is also known as the Open Government Data Act. And it basically establishes a centralized catalog or index of every agency’s federal data assets.
And previously, there had been an initiative started by the Obama administration that launched Data.gov that is hosted by GSA. Now, Data.gov did not serve as a repository. This is not where data is being deposited in the sense of, like, an institutional repository that many libraries are most familiar with. And instead, it just pulled in the information that agencies were indexing on their own inventories of data.
And so when the Foundations for Evidence-Based Policymaking Act was passed, it just made a lot of sense, right, to take advantage of the infrastructure that Data.gov provided. And so what we like to characterize it as is that Data.gov provides the Federal Data Catalog. And so the relationship is that Data.gov is the landing place for the Federal Data Catalog.
The Federal Data Catalog is comprised of an aggregation of what are known in the statute, in the Open Government Data Act, as agency comprehensive data inventories. This is just an index of every data asset they hold, but not the data themselves.
They [federal agencies] are under-resourced in terms of budget and staffing, and it would take an army for every agency to be able to do this comprehensively.
Public Data Project:
Okay, so I understand it’s not a repository, but I don’t understand completely why it’s not comprehensive. I mean, the words you just used would make me think that if every agency is submitting their indices, why isn’t it comprehensive?
Chris Marcum:
Yeah, this is a really good question. It comes down to the practicalities of implementation.
So today, there are over 500,000 datasets listed on Data.gov. Most of those are federal data assets. There are some data assets in there from state and local governments because Data.gov will index if they’re supplied to the GSA, the General Services Administration that administers Data.gov.
But the question about why the Federal Data Catalog isn’t comprehensive when, in fact, the federal agencies are required by statute to have a comprehensive data inventory.
And if you think about that number, around 500,000, it’s probably an order of magnitude lower than the actual number of federal data assets that federal agencies hold. And if you go back and you think about the complexity of all of the types of data and what is defined as a data asset that an agency might hold, you have to think back over the course of the history of that agency, and they might hold on to datasets for a long time. It becomes just a huge challenge to be able to index them, to digitize those. Some of those data assets are probably still on paper. Many of them have probably ended up, to some extent, in the National Archives already. And so there has been a loss of the record of those data.
And so it’s a complicated problem. It’s really challenging for an agency to be able to do a comprehensive inventory.
But the hope is that after we, and when I say “we,” [I mean] the Office of Management and Budget — while I was there, I was one of the leads of the development of an implementation guidance memo known as M-25-05, which is where we’re trying to translate Congress’s intent into an implementation strategy for the agencies to comply with the law on comprehensive data inventories.
And what’s really interesting about that is that the hope was that it would guide agencies to make sure that they have a forward-looking perspective. So everything that comes in now should be open by default, and that you should prioritize existing data assets based off of some strategies that you and your privacy officials and your chief information officers might have, and the agencies and your stakeholders might have for all the past data.
And so really it’s a forward-thinking guidance document. And so that’s why there’s under-resourcing that agencies are faced with, and the chief data officers’ staff. They’re under-resourced in terms of budget and staffing, and it would take an army for every agency to be able to do this comprehensively.
Public Data Project:
Yeah, that’s great. That’s really, really helpful and sobering to understand. Thank you for taking the time to explain that to us.
Another thing that really struck me in the report that really just rang true — my own background is in the history of bibliography. And you talk about a lack of consistent or transparent methodologies generally across the government and across the care for federal data assets. And one distinct part of that lack is in definitions — that is, clear definitions.
And you offer some helpful nuance when you distinguish between deletion, access removal, and discontinuation around federal data. That’s really important because when we’re talking about data rescue and things like that, those lines often get blurred. And it’s really important to remember how and why data might not be accessible.
But I was wondering, too, just at a very basic level, do we have a definition for federal data? Does it come down to who is collecting the data? Or because we know that contractors often do this work, is it who’s funding the collecting of the data? Something else? And then I guess I would just layer in, too, how and why might that definition matter? And I have some ideas myself related to what you were saying earlier, but I would love to hear if you had any additional thoughts on that.
Chris Marcum:
Yeah, so I wouldn’t say there’s a definition of federal data with the qualifier “federal,” but there is a definition of data in the Foundations for Evidence-Based Policymaking Act, as well as some other statutes.
And that definition is technical and a little bit boring, but — I’m going to use some acronyms — in 44 U.S.C. [3502], Congress has defined data as recorded information acquired or maintained by an agency, I believe. [Note: 44 U.S.C. 3502 defines “data” as “recorded information, regardless of form or the media on which the data is recorded”; related terms such as “data asset” refer to data maintained by an agency.] And so in the Open Government Data Act, there’s a provision that talks about recorded information, regardless of its form or the media on which the data is recorded, and that it’s acquired or maintained by the agency.
That is really important because in the modern age, we think of data as being digital, right? But this really gives a definition of data that is broader and that can include recorded information on paper, recorded information on [other media]. What I love to imagine is these new forms of data preservation where we have, like, crystals being inscribed. Or data being recorded in genomes, for example, has been a novel thing. So it’s a really broad definition.
And when you ask [about contractors], let’s say a contractor is working with the federal government and they’re collecting data. By statute, that data is owned by the federal government. It’s federal data. And so the Evidence Act, the Open Government Data Act, what is very clear is that those data assets do need to be inventoried. And any encumbrances on those data assets, let’s say that an agency partners with an organization that provides proprietary data for some services. If the agency is maintaining those data or it acquires them under whatever legal definition their lawyers can come up with, that has to be inventoried.
But the encumbrances on those data also need to be disclosed very transparently in the metadata. So the comprehensive data inventories have to say whether or not there’s copyright associated, and how the public can access it, if the public can access it, for example. I think the biggest component is transparency in that the agency has access to that data.
If data is put into an institutional repository, or is regularly used, or accessed via the cloud, there’s a good argument to say the federal agency is maintaining that data. …
Where it becomes more nebulous is on derivative datasets. And so you can imagine that you have a large corpus of data where you’ll have a dataset that lots of agencies create sub-datasets from … Are those data assets, and do they count as something being maintained?
Public Data Project:
Right, so the agency has access to it. And this word “maintained,” I might postulate, is even more nebulous than the word “preserve.” What does that mean in this context — to maintain that data?
Chris Marcum:
Yes, so does it mean that the agency has ingested it into their institutional repository? Does it mean that it’s stored on a computer in just one person’s office?
The chief data officers have to all go through this exercise where they have to figure out what the definition means to the agency’s mission. And so “maintained” here, I think, encompasses deposit in repositories. So if data is put into an institutional repository, or is regularly used, or accessed via the cloud, there’s a good argument to say the federal agency is maintaining that data.
Certainly data that are being updated, or are being cleaned, or being processed or used are also being maintained. And so that’s been a very easy one to handle.
Where it becomes more nebulous is on derivative datasets. And so you can imagine that you have a large corpus of data where you’ll have a dataset that lots of agencies create sub-datasets from: maybe bespoke use cases, or little research projects. Are those data assets, and do they count as something being maintained?
And so that becomes more of a product-focused approach to data. Is the thing that needs to be inventoried the parent dataset or any of these child datasets that might propagate after them? And that’s more complicated.
Public Data Project:
And returning to this concept of parent and child datasets, am I right to say that that is part of the reason that the numbers of datasets in Data.gov can fluctuate so wildly?
Chris Marcum:
Yeah. So one of the things that happened early on last year that got a lot of press and got attention even by members of Congress was that there was a lot of fluctuation shortly after the inauguration through the month of February on the top-level counts. Data.gov provides a top-level count, the number of data assets indexed in the Federal Data Catalog, and it was bouncing around on the order of a few thousand datasets.
And it just so happens that one of the very mundane reasons that can happen is because Data.gov is dynamic. It pulls in information from the federal agencies. And so if federal agencies are updating their comprehensive data inventories, then that will be reflected on Data.gov.
One of the big ways that that number can change is when an agency decides to put a series of data into a collection. And then historically on Data.gov, the way they handled that is — instead of enumerating every single one of the child datasets, you can imagine that there might be a project that has five datasets and they get collected into a single collection or put into a single collection. And then the inventory goes down by four because only the collection is being counted.
Now, the new iteration of Data.gov, the new update, doesn’t do that. It actually counts the individual data assets inside a collection. So this has been something that’s been desired by the community for a long time, and GSA is finally being responsive by updating Data.gov to make a more accurate reflection of the true count of datasets.
But it can happen the other way, too. You can imagine that a collection is, well, these are no longer one entity. There might be separate datasets, but there are separate maintenance tracks and update tracks, and they get broken up from a collection. That can also happen.
Public Data Project:
I just want to understand better. When you talk about Data.gov pulling in from federal agencies, is that automated? First question. And second question: how does it then relate to what you said earlier about it being statutory that this happens, that federal agencies contribute? So is it like there’s this automated process that you do or don’t sign up for? What is actually going on there with the vacuuming-in of data?
Chris Marcum:
Really good question. That is one of the mysteries in information policy.
So the way that this massive federated apparatus works — Cole Donovan and I recently wrote a piece for the Federation of American Scientists where we have a very simple sentence that I think has a lot of impact: “governing is hard.” And in this case, governing data is hard.
So I want to point your listeners to a resource, resources.data.gov, where they outline some of this process, to look at the information on data sources for Data.gov.
So what happens is the statute requires every agency to have a comprehensive data inventory. Some agencies have more than one. These become the data sources that are harvested by Data.gov. And some agencies have more than one, even though the statute says they have to have one.
Again, the complexities of implementation mean that [there are exceptions]. Like, the Census’s TIGER files have their own inventory because they’re updated with some regularity and they’re complex. And these are the shapefiles that give us our maps, basically, for the country. They’re relied upon by pretty much everything and they’re taken for granted because we all use them on Google Maps and other platforms.
And so what will happen is these inventories are promulgated at the agency level. They sit on agency servers. And then GSA has a harvesting routine that happens pretty much daily that goes through, crawls those sources, and then pulls in the information, updating its master list, which is the Federal Data Catalog.
Public Data Project:
Okay, thank you. And so then to return to the Federal Data Catalog, that’s the lodestone, the cornerstone of all of this. Thinking back, just to return to our initial conversation about its incompleteness. Were you made information czar, what would you do to make it more complete?
If we were to say that it would be a civic good to have a complete catalog, what would we do to get to that completeness?
Chris Marcum:
So I would first and foremost recognize that it is an extremely difficult task for the agencies.
And so, as I’ve said, notwithstanding resource limitations, staffing limitations, if we had some statutory authority with an appropriated budget that is sufficient to accomplish this, it would be really helpful for every agency to establish a data governance board that then goes through all of the use cases with effectively every staff member.
And we did this exercise in the Office of Management and Budget, or started to before I departed last year. But our CIO, Chief Information Officer, brought us together, about 20 or 30 of the staff members, to just talk about — hey, what data do you use? What data is important to you? What data do you store in your computer? What data do you make derivative datasets from? What do you need from us that you don’t have access to?
And that started the process for establishing a comprehensive data inventory within that office.
Establishing a data governance board that then goes out and makes sure the staff are trained in data access and management best practices, but are also aware of the need for inventorying all the data assets and to make sure the definitions for those data assets are governed — that would be what I would do. And I would make that a requirement for every agency and have the agencies report back up to, say, the Office of Management and Budget or another appropriate office as things evolve in the government.
There’s also … great expertise in the library community within the federal government. … And so greater interagency coordination is absolutely necessary for the success of this.
Public Data Project:
That’s great. Thank you. And in that work — you mentioned the National Archives, that some things go there. Of course, we’ve got our Library of Congress, which I realize has a somewhat complicated history when it comes to this kind of work. But I’m just wondering, are there library/archive institutions within the government already that would play a role here? Or is that a big lack?
Chris Marcum:
No, I think there are. I mean, it’s “yes and.” So, yes, there is a role for the National Archives. Obviously, the National Archives have to help agencies with their final disposition of all of their records and information that appear in datasets. Of course, those are records, and they are subject to the Federal Records Act for the most part.
So you have the National Archives, which has responsibilities on archiving information. They also have responsibilities for promulgating standards. They do the classification standards. And so it’s really helpful for agencies to be able to take advantage of this existing body of knowledge around, what is this? Is this controlled unclassified information? Is this secure information? And there’s already a lingua franca available.
There’s also, like you said, great expertise in the library community within the federal government. And one of the areas that I just love to talk about is that many agencies hold material collections. Obviously, we think of maybe the big ones, like the Smithsonian. There’s a huge material collection, huge libraries.
But then there are more nuanced cases like at NIST, the National Institute of Standards and Technology. They’ve got their reference materials database, a reference materials library. That is a licensed library that people pay to have access to. But they have a lot of knowledge on how to curate information in a structured manner for accessibility and preservation for the long term.
And so greater interagency coordination is absolutely necessary for the success of this. I like to even point to the fact that NIST a few years ago developed the Research Data Framework, where they provide a governance strategy for federally funded research data. And so this goes beyond just what the agency themselves are requiring or producing, to that which their grantees produce.
Public Data Project:
I’m thinking, too, another example might be the NASA Library, which of course was recently in the news and in peril, right?
Chris Marcum:
Yeah, so not all of the NASA libraries, just the library at Goddard has been shuttered. [Note: Additional NASA library closures have been reported since 2022.] And that is a tragedy because Goddard represents a wealth of material and informational assets that really require librarian stewardship over.
And to have those assets transferred either to the National Archives or probably, as the case may be now, shuttered and just locked behind a door while that process unfolds, really does not do a service to the public good. And it certainly doesn’t do a service to the researchers who rely on those resources at the lab.
I think it’s worth reflecting for a second on the ways in which the work of the government, when done best, is transparent. And that’s another way of saying it is accessible to all. … That is half of the reason that libraries exist: preservation and access, right? And so [between the government and libraries] there’s a very natural connection and shared mission in terms of the public good.
Public Data Project:
For sure. Our conversation has naturally shifted from questions around basic preservation to access. I think it’s worth reflecting for a second on the ways in which the work of the government, when done best, is transparent. And that’s another way of saying it is accessible to all. And that is the goal. That is half of the reason that libraries exist: preservation and access, right? And so there’s a very natural connection and shared mission in terms of the public good. So, yeah, that just all makes a lot of sense to me.
I would be remiss were I not to bring up metadata because we always want to talk about metadata. All roads lead to metadata. You note in your report that inaccurate metadata is a major issue, and the misclassification of datasets, and also misleading and rotting URLs, the kind of maintenance work that librarians are quite familiar with.
So I was just curious, in terms of metadata standards — I know they exist. Is that the issue, that the standards aren’t hitting it quite right? Is it an implementation issue? Is it something that’s happening in the aggregation? Where does the inaccuracy creep in? And then also the misclassification, and this obviously missing maintenance work. Lots on the table there, if you’d be willing to pick up any of that.
Chris Marcum:
I’m going to answer you with an answer I think you’re really going to appreciate. I think that the amount of, let’s just call it error, in agencies’ comprehensive data inventories is a strong indication of the need for more information scientists in those agencies, like librarians, like repository experts, to help with the curation.
Because ultimately the information in the metadata catalogs is only as good as it is entered, typically by people. And so you get a lot of errors that can occur based on human input error. You also get errors that occur when, like, a CIO migrates a system to a new server. And then all of a sudden, the links for the data sources are all broken. We’ve seen that happen in the past. An API that might serve up information about data or serve data itself might change. It might change vendors. And then that API might have a different URL propagation system. And so that can change. And so it takes time, of course. But if they had good information systems experts and information scientists available before these decisions are made, that will help tremendously with reducing the amount of error in the future.
On classification, I found this really fascinating for data in the Federal Data Catalog, because the law is not clear. And I will say that having struggled for a long time with my colleagues at OMB on how to communicate what constitutes a data asset, a public data asset, an open government data asset — these things are all in statute, but the distinction between them is not as clear as Congress could have made them. And part [of it] is probably because there certainly wasn’t an MIS or someone with an information sciences background writing the law, per se.
And so what we found is that the interpretation historically has been left up to the agencies and left up to individual subject matter experts or individual staffers. And so you get this really interesting mosaic of what gets captured as a data asset. And so it can range anywhere from a PDF of an infographic to, you know, the Census. And the diversity of that is just wild.
I think that hopefully M-25-05, the implementation guidance, provides some additional clarity on the structured nature that we expect of data. It’ll provide agencies more clarity, but they’ll also exercise more care in classifying their assets as they go through their prioritization of which assets need to move from federal data assets to public to open government data assets.
And again, it’s a tough problem. The other part of me is like, I love the fact that I can find, for example, CDC’s anti-smoking infographics on the Federal Data Catalog. But I just don’t think they belong there. And so it’s like, I love that they’re preserved and that they’re available. But are they data assets?
And so if you don’t preserve that data, then the tools, as you said, are kind of useless, right? Because they don’t have the high-quality information that you require. On the other hand, I am a strong believer in democratizing data and making it accessible and approachable to people.
Public Data Project:
Right. You talk in the report in really helpful ways about the distinction between data tools and data sources. And what is it that we need to be advocating for? The tools are amazingly powerful and they’re wonderful. And yet without the data behind them, there’s no there there.
Chris Marcum:
Yeah, it’s so fascinating because what enables many of the tools that have been taken down by this administration and put back up by civic society organizations is the fact that the underlying data have remained publicly accessible and were publicly accessible, publicly available.
And so if you don’t preserve that data, then the tools, as you said, are kind of useless, right? Because they don’t have the high-quality information that you require.
On the other hand, I am a strong believer in democratizing data and making it accessible and approachable to people. Denice Ross and I recently produced and published a Federal Data Field Guide. It helps to make federal data just more approachable. And it is, in effect, a type of data tool because it’s like an aggregation of all of these different data types. It provides an ontology.
I really do have an appreciation for democratization. I think the data tools really do provide that accessibility. And I think the modus operandi of this administration is to increase friction in the approachability of publicly accessible data. And so if you take down the tools that help everyday people interpret federal data, I think that’s part of the goal — even if you maintain access to the online data itself. So I’m right there with you. And the distinction is really important and it needs to be emphasized. Ultimately, if we’re targeting preservation, we definitely have to handle the underlying data because without the data, you don’t have the tools.
And I’d also want to add in another nuance and something I think a lot about, as when I was a senior statistician and senior scientist at OMB, is data reports. Data tools, typically, are interactive, and they help you interpret. But a lot of the economy relies on economic reports where the underlying data are confidential statistical data. They’re not readily publicly accessible. You have to go through a clearance process to get access to them, either through the Federal Statistical Research Data Center program or through the agency research data centers themselves. And there are costs associated with that. You have to be licensed and get clearance.
And so instead, what the agencies do is they create these wonderful aggregated quarterly, monthly, yearly reports that provide aggregated statistical data and information.
Many economists, many reporters, they consider that to be data, right? This is the federal economic data. It is not the dataset that underlies those data. It’s just the aggregations. And so that’s another really important nuance I didn’t talk about in my report, but is one that we have to really think about because these are costly. And the statistical agencies that produce them are under resource constraints and under threat.
Not only are data about people, but the entire data infrastructure relies on people. And the reduction in workforce capacity? There is irreplaceable, non-AI-replaceable damage that has been done.
Public Data Project:
Exactly. And the level of expertise it takes to produce them — the people who really know the data.
I’ll just ask one last question. What I’d love to close our conversation around is federal workers. And we’re not too far away from May Day to honor federal workers. As you know, I was DOGE’d myself a year ago, so this is a topic very close to my heart.
I’m going to embarrass you a little bit and quote from your own writing, because I was really struck by these sentences. You write, “By hollowing out subject matter experts and other critical staff across agencies, the administration reduced data integrity capacity in a systemic manner. Ultimately, this systemic disruption created lasting deficits in the nation’s ability to reliably collect, protect, and disseminate the vital data necessary for informed policymaking, economic forecasting, and scientific research.” I just thought that really summed it up in a lovely way.
So I wanted to see if you had any closing reflections on the relationship between the precarity of federal data and the slashing of the federal workforce.
Chris Marcum:
Not only are data about people, but the entire data infrastructure relies on people. And the reduction in workforce capacity? There is irreplaceable, non-AI-replaceable damage that has been done in this current administration to the federal workforce.
And you see some recalcitrance by the administration at this point in acknowledging that, where the Office of Personnel Management is touting that they’re going to hire thousands of tech workers. But they had just fired, like 300,000. Or 300,000 or so had departed.
So I would say, first and foremost, this is Public Service Recognition Week. And the public servants like you and myself, whether you have departed the federal workforce by your own volition, like myself, or not, like yourself, I think it’s incredibly important to recognize that subject matter expertise is absolutely essential for the integrity of federal data and for the integrity of maintaining public access to federal data.
Public Data Project:
That’s great. Thank you so much. And I think that’s the perfect place to end. And I just want to say thank you so much for your work.
And again, to give a shout out to The Integrity of Public Access to Federal Data, this fabulous report that Chris recently published. And we encourage everyone generally to pay attention to your work, because it’s just so valuable to all of us on so many levels. So thank you.
Chris Marcum:
Well, thank you, Molly, and thanks to your project and the great work that you all are doing with both the Data.gov project and everything that LIL is doing. I really appreciate it and really appreciate the opportunity to talk to you.
]]>
Molly HardyOn May 7, 2026, Molly Hardy, Project Lead for the Public Data Project, sat down for an interview with Chris Marcum, Senior Fellow for Data Policy at the Data Foundation and former Senior Statistician at the White House Office of Management and Budget. Please click the video above to listen and watch; the interview transcript below has been lightly edited for clarity.]]>
Launching the Agent Protocols Tech Tree2026-02-23T00:00:00+00:002026-02-23T00:00:00+00:00https://lil.law.harvard.edu/blog/2026/02/23/agent-protocols-tech-tree/
Today I am sharing the Agent Protocols Tech Tree. APTT is a visual, videogame-style tech tree of the evolving protocols supporting AI agents.
Where did this come from?
I made the APTT for a session on “The Role of Protocols in the Agents Ecosystem” at the Towards an Internet Ecosystem for Sane Autonomous Agents workshop at the Berkman Klein Center on February 9th.
It’s a video game tech tree because, while the word “protocols” is boring, the phenomenon of open protocols is fascinating, and I want to make them easier to approach and explore.
What is an open protocol? Why care about them?
An open protocol is a shared language used by multiple software projects so they can interoperate or compete with each other.
Protocols offer an x-ray of an emerging technology — they tell you what the builder community actually cares about, what they are forced to agree on, what is already done, and what is likely to come next.
Open protocols go back to the founding of the internet when basic concepts like “TCP/IP” were standardized — not by a government or company creating and enforcing a rule, but by a community of builders based on “rough consensus and running code.” On the internet no one could force you to use the same standards as everyone else, but if you wanted to be part of the same conversation, you had to speak the same language. That created strong incentives to agree on protocols, from SMTP to DNS to FTP to HTTP to SSL. By tracing each of those protocols, you could see the evolving concerns of the people building the internet.
(For a great discussion of that history, see “The Battle of the Networks” from LIL faculty director Jonathan Zittrain’s book “The Future of the Internet — and How to Stop It.”)
Why are protocols so important for AI agents?
Like the early internet, AI agents today are an emerging, distributed phenomenon that is changing faster than even experts can understand. We’re holding workshops with names like “Towards an Internet Ecosystem for Sane Autonomous Agents” because no one really knows what it will mean to have millions of semi-autonomous computer programs acting and interacting in human-like ways online.
Also like the early internet, it’s tempting to look for some government or company that is in charge and can tame this phenomenon, set the rules of the road. But in many ways there isn’t one. The ingredients of AI agents are just not that complex or that controlled.
This makes sense if you look at Anthropic’s definition of an agent, which is simply “models using tools in a loop.” That is not a complex recipe: it requires a large language model, of which there are now many, including powerful open source ones that can run locally; a fairly small and simple control loop; and a set of “tools,” simple software programs that can interact with the world to do things like run a web search or send a text message. “Agents” as a phenomenon are a technique, like calculus, not a service, like Uber.
That makes agents hard to regulate, and makes protocols incredibly important. It is protocols that give agents the tools they use. It is protocols that the builder community are developing as fast as they can to increase what agents can do. If you want to nudge this technique toward human thriving, it is protocols that might most shape agent behavior by making some agents easier to build than others.
To be sure, protocols aren’t the only way to influence technological development. Larry Lessig’s classic “pathetic dot theory” outlines markets, laws, social norms, and architecture as four separate ways that individual action gets regulated, and protocols are just an aspect of architecture. But the more a technology is dispersed and simple to recreate, the more protocols come into play in how it evolves.
How do I use the APTT?
APTT is designed to be helpful whether you’re a less-technical person who just wants to understand what agents are, or a more technical person who wants to understand exactly what’s getting built.
Either way the pile of agent technologies is confusing, so I recommend starting at the beginning with “Inference API.”
Video games are often designed so you start with a simple feature unlocked and then progressively unlock more and more complex options as you learn the game. The same approach works here: imagine that you have just unlocked “Inference API” in this game, and once you’re comfortable with that, explore off to the right to see how each protocol enables or necessitates the next.
You can click each technology to learn what problem it solves (why did people need something like this?), how it’s standardizing (who kicked this off?), and what virtuous cycle it enabled (why did other people want to get on board?).
You can also see visual animations of how the protocol is used — what messages are actually sent back and forth between who?
If you’re interested in the technical details, you can click any of the messages to see at a wire level what’s actually happening. (Often, something simpler than it sounds.)
As you move off to the right, you’ll go from widely adopted technologies, like MCP, to technologies that have commercial supporters but not much social proof yet, like Visa TAP, or technologies that don’t even exist but might make sense in the future, like Interoperable Memory, Signed Intent Mandates, or Agent Lingua Franca.
The ragged edge on the right is where I hope you’ll be the most critical: what seems inevitable, what seems like a dead end, and what would you like to see more of?
How accurate is all of this? How do I fix mistakes?
APTT is a work in progress, and to be honest in many ways is a whiteboard sketch. I put it together (and vibe coded much of it) to help support a conversation, first at the workshop and now online. I think whiteboard sketches are useful, so I’m sharing it, but I don’t pretend it’s authoritative; it’s just my rough sense of how things work right now.
(This is a weird thing about the agentic moment — my coding agent has made this tool look more polished and complete than it may really deserve. Think napkin sketch with fancy graphics.)
If you think I got things wrong or missed part of the story, please open an issue on the GitHub repository. I plan to keep this rough and opinionated, and focused on consensus-driven protocols as a lens for understanding what’s happening — so I’ll either pull contributions into the main tool, or just leave them as discussions to represent the range of opinions about how all of this works. I hope it’s fun to play with either way.
]]>
Jack Cushman]]>
Replication of Government Datasets and the Principles of Provenance2025-12-10T20:00:00+00:002025-12-10T20:00:00+00:00https://lil.law.harvard.edu/blog/2025/12/10/replication-of-government-datasets-and-the-principles-of-provenance/As part of our Public Data Project, LIL recently launched Data.gov Archive Search. In this post, we consider the importance of provenance for large, replicated government datasets. This post is the third in a three-part series; the first introduces Data.gov Archive Search and the second explores its architecture.
In cultural heritage collecting, objects’ histories matter; we care who owned what, where, and when. The chronology of possession of an object through place and time is commonly referred to as “provenance.” Efforts to decolonize the archive have given new life to this age-old collecting concept, as provenance is now often at the forefront of collecting conversations: tracing how and why an object came to be placed (or displaced) in a given museum, library, or collection often is intertwined with histories of colonialism and its accompanying plunder. Projects such as Art Tracks, Archives Directory for the History of Collecting in America, and Getty Provenance Index help to record provenance information and to share it across institutions and platforms. Other projects, such as Story Maps of Cultural Racketeering, depict the underbelly of the trade in cultural heritage objects.
Recovery of art stolen by the Nazis, dramatized in films such as The Monuments Men, has brought the concept of “provenance” into the public conversation as well as the courtroom. Many of the legal claims for restitution have been adjudicated based on provenance records.
The provenance of digital collections might seem trivial when compared to such monumental moments. And yet, stories like this have been on my mind as we develop the Public Data Project. How and why could provenance of federal data be needed in the future? When might digital provenance — the marrying of ownership metadata to the digital object itself — matter? Could we imagine it being used to right past wrongs, to return objects to their rightful places, to restore justice?
In the context of government data, provenance most often refers to which government agency or office produced the data. When government data was widely distributed on paper, it was nearly impossible to forge government records — too many legitimate copies existed. In the digital environment, provenance is not so straightforward. Metadata tells us what the source of a given dataset is. But this data is in the public trust, and so its origins are only the beginning of its provenance story. What happens when we start to copy federal data and pass it from hand to hand, so that trusting it means not only trusting the agency that produced it but also those that copied it, stored it, and are serving it up?
As we develop the Public Data Project, we have been considering provenance anew: what provenance data should we record when private institutions, or members of the public, download and preserve public data from their governments? Put another way: if we as non-government actors make government data available to others, how do we maintain trust that this data is authentic, an exact copy of that which was released by the government?
There could be a time in the future when we are just as interested in the changes and inventions of the people who pass government data from hand to hand as we are in the original, unaltered sources. As stewards of federal data, we must then have a responsibility to trace and report data’s ownership histories. This seems, in some ways, even more true because of the very nature of data: it holds mimetic potential. These datasets not only want to be used, but they want to be reproduced. The Enlightenment tradition that vaunts of originality — of an essence that defines an object and that cannot be replicated — seems misplaced here if the dataset remains unchanged from its source version to its replicated versions. In the spirit of scholars such as Marcus Boon who write in praise of “copying,” we might then say that replications of the data are not denigrated at all, just because they are not the original set. And yet, at the same time, we want and need data to retain authority, to know its origin stories. How best to do this?
Wax seal of “De Twentsche Bank” in the Netherlands. Source: Wikimedia Commons.Screenshot of a metadata record in LIL’s Data.gov Archive.
Those signatures, and the metadata they sign, are one part of publishing robust, resilient archives with irrefutable provenance marks. Through digital signatures that are verifiable using public-key encryption, as well as metadata JSON files that contain details of source and ownership, each dataset has a clear custodial history. Regardless of how users acquire the data, they can check that copies of the “original” datasets — which were first published on a government website, then aggregated to Data.gov, and then replicated by LIL — are unchanged since that point.
When seen through the lens of provenance, characteristics like authenticity, integrity, reliability, and credibility still matter in digital environments. Just as we would seek to authenticate Raphael’s Portrait of a Young Man should it turn up at auction after 80 years, so too must we carefully certify our digital cultural heritage.
]]>
Molly HardyAs part of our Public Data Project, LIL recently launched Data.gov Archive Search. In this post, we consider the importance of provenance for large, replicated government datasets. This post is the third in a three-part series; the first introduces Data.gov Archive Search and the second explores its architecture.]]>
Rethinking Data Discovery for Libraries and Digital Humanities2025-10-24T20:00:00+00:002025-10-24T20:00:00+00:00https://lil.law.harvard.edu/blog/2025/10/24/rethinking-data-discovery-for-libraries-and-digital-humanities/Woman using a Macey vertical filing cabinet (detail, 1903). Source: Wikimedia Commons.
Rethinking the Old Trade-Off: Cost, Complexity, and Access
Libraries, digital humanities projects, and cultural heritage organizations have long had to perform a balancing act when sharing their collections online, negotiating between access and affordability. Providing robust features for data discovery, such as browsing, filtering, and search, has traditionally required dedicated computing infrastructure such as servers and databases. Ongoing server hosting, regular security and software updates, and consistent operational oversight are expensive and require skilled staff. Over years or decades, budget changes and staff turnover often strand these projects in an unmaintained or nonfunctioning state.
The alternative, static file hosting, requires minimal maintenance and reduces expenses dramatically. For example, storing gigabytes of data on Amazon S3 may cost $1/month or less. However, static hosting often diminishes the capacity for rich data discovery. Without a dynamic computing layer between the user’s web browser and the source files, data access may be restricted to brittle pre-rendered browsing hierarchies or search functionality that is impeded by client memory limits. Under such barriers, the collection’s discoverability suffers.
For years, online collection discovery has been stuck between a rock and a hard place: accept the complexity and expense required for a good user experience, or opt for simplicity and leave users to contend with the blunt limitations of a static discovery layer.
Why We Explored a New Approach
When LIL began thinking about how to provide discovery for the Data.gov Archive, we decided that building a lightweight and easily maintained access point from the beginning would be worth our team’s effort. We wanted to provide low-effort discovery with minimal impact on our resources. We also wanted to ensure that whatever path we chose would encourage, rather than impede, long-term access.
This approach builds on our recent experience when the Caselaw Access Project (CAP) hit a transition moment. At that time, we elected to switch case.law to a static site and to partner with others dedicated to open legal data to provide more feature-rich access.
CAP includes some 11 TB of data; the Data.gov Archive represents nearly 18 TB, with the catalog metadata alone accounting for about 1 GB. Manually browsing the archive data in its repository, even for a user who knows what she’s looking for, is laborious and time-consuming. Thus we faced a challenge. Could we enable dynamic, scalable discovery of the Data.gov Archive while enjoying the frugality, simplicity, and maintainability of static hosting?
Our Experiment: Rich Discovery, No Server Required
Recent advancements in client-side data analysis led us to try something new. Tools like DuckDB-Wasm, sql.js-httpvfs, and Protomaps, powered by standards such as WebAssembly, web workers, and HTTP range requests, allow users to efficiently query large remote datasets in the browser. Rather than downloading a 2 GB data file into memory, these tools can incrementally retrieve only the relevant parts of the file and process query results locally.
We developed Data.gov Archive Search on the same model. Here’s how it works:
Data storage: We store Data.gov Archive catalog metadata as sorted, compressed Parquet files on Source.coop, taking advantage of performant static file hosting.
In-browser query engine: Our client-side web application loads DuckDB-Wasm, a fully functional database engine running inside the user’s browser.
On-demand data access: When a user navigates to a resource or submits a search, our DuckDB-Wasm client executes a targeted retrieval of the data needed to fulfill the request. No dedicated server is required; queries run entirely in the browser.
This experiment has not been without obstacles. Getting good performance out of this model demands careful data engineering, and the large DuckDB-Wasm binary imposes a considerable latency cost. As of this writing, we’re continuing to explore speedy alternatives like hyparquet and Arquero to further improve performance.
Still, we’re pleased with the result: an inexpensive, low-maintenance static discovery platform that allows users to browse, search, and filter Data.gov Archive records entirely in the browser.
Why This Matters for Libraries, Digital Humanities Projects, and Beyond
This new pattern offers a compelling model for libraries, academic archives, and DH projects of all sizes:
Lower operating costs: By shifting from an expensive server to lower cost static storage, projects can sustainably offer their users access to data.
Reduced technical overhead: With no dedicated backend server, security risks are reduced, no patching or upgrades are needed, and crashing servers are not a concern.
Sustained access: Projects can be set up with care, but without demanding constant attention. Organizations can be more confident that their archive and discovery interfaces remain usable and accessible, even as staffing or funding changes over time.
Knowing that we are not the only group interested in approaching access in this way, we’re sharing our generalized learnings. We see a few ways forward for others in the knowledge and information world:
Prototype or pilot: If your organization has large, relatively static datasets, consider experimenting with a browser-based search tool using static hosting.
Share and collaborate: Template applications, workflows, and lessons learned can help this new pattern gain adoption and maturity across the community.
This project is still evolving, and we invite others—particularly those in libraries and digital cultural heritage—to explore these possibilities with us. We’re committed to open sharing as we refine our tools, and we welcome collaboration or feedback at lil@law.harvard.edu.
In February, the Library Innovation Lab announced its archive of the federal data clearinghouse Data.gov. Today, we’re pleased to share Data.gov Archive Search, an interface for exploring this important collection of government datasets. Our work builds on recent advancements in lightweight, browser-based querying to enable discovery of more than 311,000 datasets comprising some 17.9 terabytes of data on topics ranging from automotive recalls to chronic disease indicators.
Traditionally, supporting search across massive collections has required investment in dedicated computing infrastructure, such as a server running a database or search index. In recent years, innovative tools and methods for client-side querying have opened a new path. With these technologies, users can execute fast queries over large volumes of static data using only a web browser.
This interface joins a host of recent efforts not only to preserve government data, but also to make it accessible in independent interfaces. The recently released Data Rescue Project Portal offers metadata-level search of the more than 1,000 datasets it has preserved. Most of these datasets live in DataLumos, the archive for valuable government data resources maintained by the University of Michigan’s Institute for Social Research.
LIL has chosen Source Cooperative as the ideal repository for its Data.gov archive for a number of reasons. Built on cloud object storage, the repository supports direct publication of massive datasets, making it easy to share the data in its entirety or as discrete objects. Additionally, LIL has used the Library of Congress standard for the transfer of digital files. The “BagIt” principles of archiving ensure that each object is digitally signed and retains detailed metadata for authenticity and provenance. Our hope is that these additional steps will make it easier for researchers and the public to cite and access the information they need over time.
In the coming month, we will continue our work, fine-tuning the interface and incorporating feedback. We also continue to explore various modes of access to large government datasets, and so we are exploring, for example, how we might create greater access to the 710 TB of Smithsonian collections data we recently copied. Please be in touch with questions or feedback.
]]>
In February, the Library Innovation Lab announced its archive of the federal data clearinghouse Data.gov. Today, we’re pleased to share Data.gov Archive Search, an interface for exploring this important collection of government datasets. Our work builds on recent advancements in lightweight, browser-based querying to enable discovery of more than 311,000 datasets comprising some 17.9 terabytes of data on topics ranging from automotive recalls to chronic disease indicators.]]>
Expanding Our Public Data Project to Include Smithsonian Collections Data2025-09-18T16:00:00+00:002025-09-18T16:00:00+00:00https://lil.law.harvard.edu/blog/2025/09/18/expanding-our-public-data-project-to-include-smithsonian-collections-data/Smithsonian Institution building, from Wikimedia Commons
We are excited to announce today that the Library Innovation Lab has expanded our Public Data Project beyond datasets available through Data.gov to include 710 TB of data from the Smithsonian Institution — the complete open access portion of the Smithsonian’s collections. This marks an important step in our long-running mission to preserve large scale public collections both for our patrons and for posterity.
From the National Museum of American History. Creative Commons 0 License
The Smithsonian has had the mission, since its founding in 1846, to pursue “the increase and diffusion of knowledge.” In the past, this could only be done by visiting Smithsonian museums in person. Now that its collections are also digital, we are grateful to be able to do our part in preserving and sharing our nation’s cultural heritage.
Our initial collection includes some 5.1 million collection items and 710 TB of data. As is always our practice, we have cryptographically signed these items to ensure provenance and are exploring resilient techniques to share access to them, which we plan to launch in the future.
From the National Museum of African American History and Culture. Creative Commons 0 License
]]>
Molly Hardy
We are excited to announce today that the Library Innovation Lab has expanded our Public Data Project beyond datasets available through Data.gov to include 710 TB of data from the Smithsonian Institution — the complete open access portion of the Smithsonian’s collections. This marks an important step in our long-running mission to preserve large scale public collections both for our patrons and for posterity.]]>
Live and Let Die: Rethinking Personal Digital Archiving, Memory, and Forgetting Through a Library Lens2025-08-20T23:06:00+00:002025-08-20T23:06:00+00:00https://lil.law.harvard.edu/blog/?p=20
In today’s world, each moment generates a digital trace. Between the photos we take, the texts we send, and the troves of cloud-stored documents, we create and accumulate more digital matter each day. As individuals, we hold immense archives on our personal devices, and yet we rarely pause to ask: What of this is worth keeping? And for how long? Each text we send, document we save, or photo we upload quietly accumulates in the digital margins of our daily routines. Almost always, we intend to return to these traces later. Almost never do we actually return to them.
Libraries do not collect and store everything indiscriminately. They are bastions of selection, context, and care. So why don’t we do the same when managing our personal digital archives? How can library principles inform personal archiving practices when memory becomes too cheap, too easy, and too abundant to manage? What does meaningful digital curation look like in an age of “infinite” storage and imperfect memory? How might we better navigate the tension between memory and forgetting in the digital age? At LIL, we’re interested in holding space for these tensions and exploring the kinds of tools and frameworks that help communities navigate these questions with nuance, care, and creativity. We researched and explored what it could look like to provide individuals with new kinds of tools and frameworks that support a more intentional relationship with their digital traces. What emerged is less a single solution and more a provocation about curation, temporality, and what it means to invite forgetting as part of designing for memory.
This blog post sketches some of our ideas and questions informed by the work of archivists, librarians, researchers, coders, and artists alike. It is an invitation to rethink what it means to curate the digital residue of our everyday lives. Everyone, even those outside of libraries, archives, and museums (LAMs), should engage in memory work with their own personal digital archives. How might we help people rigorously think through the nature of digital curation, even if they aren’t already thinking of themselves as archivists or librarians of their personal collections? We hope what follows offers a glimpse into our thinking-in-progress and sparks broader conversation about what communities and individuals should do with the sprawling, often incoherent archives our digital lives leave behind.
Our premise: overaccumulation and underconsideration
We live in a time of radical abundance when it comes to digital storage. Cloud platforms promise virtually unlimited space. A single smartphone can hold thousands of photos. Machines never forget (at least, not by default) and so we hold on to everything “just in case,” unsure when or why we might need it. Often, we believe we are preserving things such as emails, messages, and files, because we’re simply not deleting them.
But this archive is oddly inhospitable. It’s difficult to find things we didn’t intentionally label or remember existed. Search functions help us find known items, but struggle with the forgotten. Search is great for pinpointing known things like names or keywords, but lost among our buried folders and data dumps are materials we didn’t deliberately catalog for the long-term (like screenshots in your photos app). One distinction that emerged in our work is the difference between long-term access and discovery or searchability. You might have full-text search capability over an inbox or drive, but without memory of what you’re looking for or why it mattered, it won’t appear. Similarly, even when content resurfaces through algorithmic recommendation, it often lacks appropriate context.
And so, we are both overwhelmed and forgetful. We save too much, but know too little about what we’ve saved. Digital infrastructure has trained many of us to believe that “saving” is synonymous with “remembering,” but this is a design fiction. People commonly assume that “they can keep track of everything,” “they can recognize the good stuff,” and most of all, “they’re going to remember what they have!” But in practice, these assumptions rarely hold true. The more we accumulate, the less we can truly remember. Not because the memories aren’t saved, but because they are fundamentally disconnected from context.
A library lens on everyday personal digital archives
“Not everything that is dead is meant to be alive.”
When it comes to our digital lives, we often feel pressure to rescue every bit of data from entropy. But what if some data is just refuse, never meant to be remembered? In libraries and archives, we don’t retain every book, document, or scrap of marginalia. We acquire with purpose, discard items and weed our collections with care, organize our collections, and provide access with users in mind. Digitally, this process can be much harder to implement because of the sheer volume of material. Everything is captured whether it be texts, searches, or half-finished notes. Some of it may be precious, some useful, and some exploitable.
The challenge is thus cultural as much as technical. What deserves preservation? Whose job is it to decide? And how can we create tools that align with people’s values, rather than simply saving everything? Libraries and archives are built on principles of deliberate acquisition, thoughtful organization, and selective retention. What if we followed those same principles in our personal digital ecosystems? Can we apply principles like curation, appraisal, and mindful stewardship from library science to personal digital archives? What if, instead of saving everything permanently by default, we adopted a mode of selective preservation rooted in intention, context, and care?
Integral to memory work is appraisal, deciding what is worth keeping. In archival theory, this is a complex, value-laden practice. As the Society of American Archivists (SAA) notes, archivists sometimes use the term “enduring value{: target=“_blank” rel=“noopener”}” rather than “permanent value” with intention, signaling that value may persist for a long time, but not necessarily forever. Notions of “enduring value” can shift over time and vary in different communities.
On forgetting (and why it’s valuable)
In digital systems, forgetting often has to be engineered. Systems are designed to store and resurface, not to decay. But decay, entropy, and obsolescence are part of the natural order of memory. If we accept that not everything needs to be held forever, we move into the realm of intentional digital gardening.
“What if forever isn’t the goal? What’s the appropriate level of preservation for a given context?”
Preservation need not be permanent in all cases. It can be revisited, adjusted, revised with time as people, contexts, and values change. Our tools should reflect that. What if temporary preservation was the more appropriate goal? What if the idea of a time capsule was not just about novelty and re-surfacing memory, but instead core to a practice of sustainable personal archiving, where materials are sealed for a time, viewed in context, then allowed to disappear?
“The memory needs to be preserved, not necessarily the artifact.”
There’s a growing recognition in library and archival science that resurfacing content too easily, and out of context, can be damaging, especially in an era where AI searches can retrieve texts without context. Personal curation tools should assist in the caretaking of memory, not replace it with AI. Too often, we see narratives that frame technology as a substitute for curation. “Don’t worry about organizing,” we’re told, “We’ll resurface what you’ll want to remember.” But this erases the intentionality fundamental to memory-making. Sometimes, forgetting protects. Sometimes, remembering requires stewardship, not just storage.
Designing for memory: limits as creative force
Designing for memory is ultimately a human-centered challenge. Limitations can be a tool, not a hindrance, and constraints can cultivate new values, behaviors, and practices that prioritize deliberate choice and intentional engagement.
Imagine creating a digital time capsule designed for memory re-encountering, temporality, and impermanence. You can only choose 10 personal items to encapsulate for future reflection. What would you choose? What story would those items tell? Would they speak to your accomplishments? Your values? Your curiosities? Would they evoke joy or loss?
Capsules could be shaped around reflective prompts to aid selection and curation:
What story or feeling do you want to preserve? What emotional tone does this capsule carry: celebration, remembrance, grief, joy?
Who is your audience: your future self, family, a future researcher, a larger community?
What context needs to be retained for future understanding?
What kind of media captures this best: text, photo, audio, video, artifacts? Why did you choose what you did?
What items would you miss the most if digital platforms went down or the items became unavailable? (Make a list).
Should these items be available immediately, or unlocked after a certain amount of time?
Once opened, should the capsule remain accessible, or eventually disappear?
Engaging in reflection like this can help individuals perform the difficult and deeply human work of curating your personal digital archive without being overwhelmed by the totality of your digital footprint. Making this kind of digital housekeeping part of your established maintenance routine (like spring cleaning) helps make memory work an intentional and active process that encourages curation, self-reflection, and aids the process of choosing what not to keep. It is memory with intention.
Memory craft: a call to action
In every era, humans have sought ways to preserve what’s vital, and let the nonessential fall away. In our current digital context, that task has become harder, not because of lack of space, but because of lack of frameworks. Your life doesn’t have to be backed up in its entirety. It only needs to be honored in its essentials. Sometimes, that means creating a space in which to remember. Sometimes, that means creating a ritual in which to let go.
At the Library Innovation Lab, we are continuing to explore what it means to help people preserve with intention. Becoming active memory stewards means moving beyond default accumulation and choosing with care and creativity what stories and traces to carry forward. We want to make memory, not just data, something people can shape and steward over time. Not everything needs to be preserved forever, and our work is to provide people with the frameworks and tools to make these decisions.
Resources
The following resources helped shape our thinking and approach to intentional curation of personal archives in the digital age:
We would like to thank our colleagues Clare Stanton, Ben Steinberg, Aristana Scourtas, and Christian Smith for the ideas that emerged from our conversations together.
Visual by Jacob Rhoades.
]]>
]]>
LIL Awarded AALL Public Access to Government Information Award2025-07-30T00:00:00+00:002025-07-30T00:00:00+00:00https://lil.law.harvard.edu/blog/2025/07/30/lil-awarded-aall-public-access-to-government-information-award/
This past week members of the Library Innovation Lab team traveled to Portland, Oregon to receive the Public Access to Government Information Award from AALL for our data.gov archive.
This award is given every year at the American Association of Law Libraries’ annual meeting to “recognize persons or organizations that have made significant contributions to protect and promote greater public access to government information.”
The Harvard Law School Library has collected government records and made them available to patrons for centuries, and we are proud to have our contribution to this work recognized by our colleagues at AALL.
]]>
LIL Team
This past week members of the Library Innovation Lab team traveled to Portland, Oregon to receive the Public Access to Government Information Award from AALL for our data.gov archive.]]>


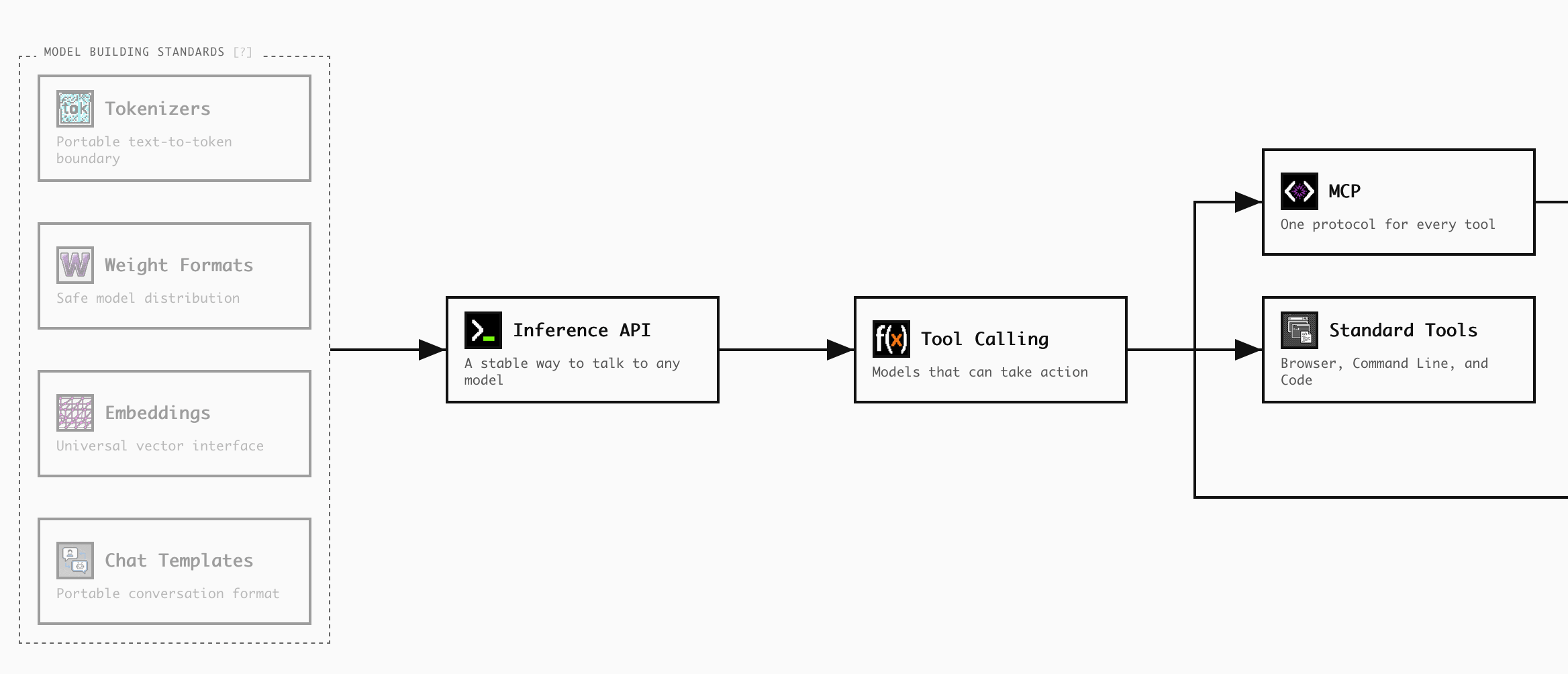

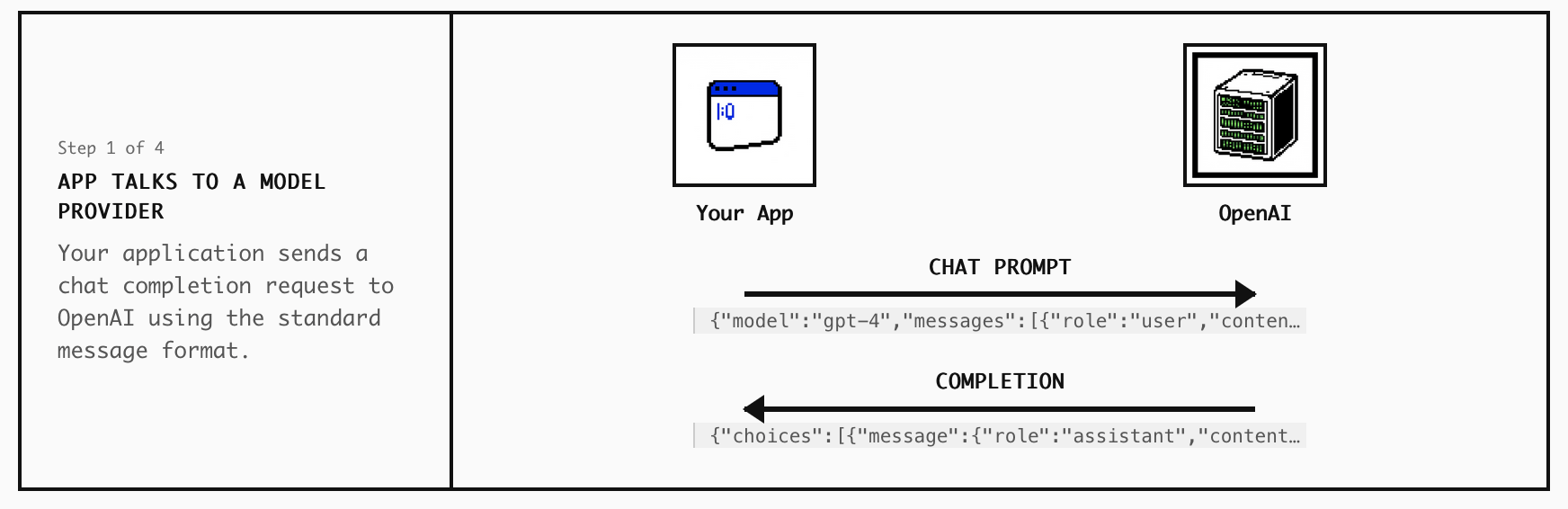




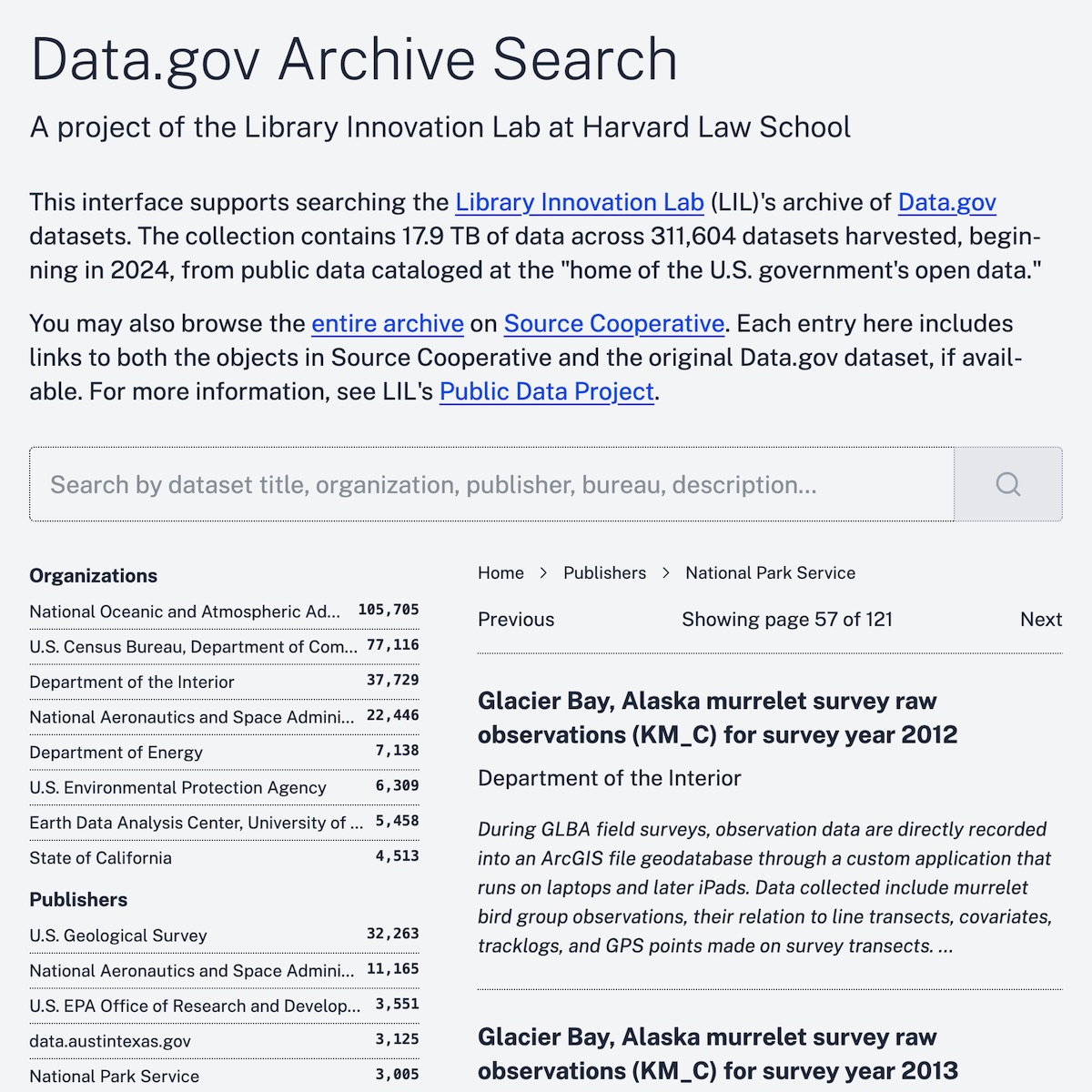






{kind=link}